어느 서비스든 마찬가지로 운영됨에 따라 누적으로 쌓이는 데이터들이 존재합니다. 저의 경우에는 메시지 테이블이 그러하였는데, 총 row가 약 50m을 넘었습니다. 따라서, 메시지의 검색 날짜기간을 길게 해둔다면 결과가 나오는데까지 15초 이상이 걸리기도 하였습니다. (첫 검색 이후에는 약 2초 내외로 걸렸습니다.)
실제로 검색 기능은 자주 이용되기 때문에 개선이 필요하다고 생각되어 Django에서 퍼포먼스를 향상시켜보기로 하였습니다.
1. 프로파일링이 먼저
테이블의 row수가 절대적으로 많기 때문에 당연히 검색은 느릴 것이라고 생각되었습니다. 하지만, 생각하는 것과는 다른 곳이 문제였던 일이 종종 있었기에 프로파일링을 앞서 진행하였습니다.
Query Inspector, silk, cProfile, Debug toolbar를 활용하여 프로파일링 해보니 크게 2가지 정도가 눈에 띄었습니다.
- ORM N+1 Problem
- 느린 SQL 실행 속도
우선, 중복으로 발생되는 쿼리를 제거하는 것이 옳다고 판단하였습니다.
(N+1 Problem은 지난 포스팅에서 잠깐 다뤄본 주제입니다.)
https://leffept.tistory.com/311
[Django]Django ORM과 QuerySet의 특징 (LazyLoading, Caching, EagerLoading)
이번 포스팅에서는 장고를 사용하게되면 필연적으로 접할 수 밖에 없는 Django의 ORM과 QuerySet의 특징에 대해 알아보려고 한다. 그 중에서도 LazyLoading, Caching, EagerLoading에 대해 알아볼 것이다. 이
leffept.tistory.com
1-1. N+1 Problem 해결하기
우선, 중복으로 발생되는 쿼리를 제거하는 것을 선행하였습니다. 소스코드는 간략하게 이해가 될 정도로만 소개하겠습니다.
class MessageViewSet(viewsets.ModelViewSet):
queryset = Message.objects
def list(self, request, *args, **kwargs):
messages = (self.get_queryset()
.select_related()
.prefetch_related())
...MessageViewSet내의 list함수에서 검색 결과를 filtering 해주는 로직이 존재합니다. 메시지 테이블은 각 모델과의 1:1, 1:N, N:M 등 다양한 관계를 가지고 있습니다.(댓글 등)
이렇게 관계를 맺고 있을 때 N+1 Problem이 쉽게 일어날 수 있기 때문에 select_related(), prefetch_related()를 활용하여 Eager Loading으로 해결하였습니다.
다만, ContentType으로 GenericForeignkey를 맺은 필드도 존재하였는데, 이 곳에서 발생되는 쿼리에서는 Eager Loading이 되지 않아 해당 부분도 찾아 처리를 해주었습니다.
class ContentObjectField(serializers.RelatedField):
def to_representation(self, value):
if isinstance(value, Comment):
comment = Comment.objects.select_related().get(id=value.id)
return CommentSerializer(comment).data이런식으로 Query Inspect에서 보여지는 Traceback을 통해 N+1 Problem이 문제가 될만한 요소들을 전부 제거를 해주었습니다.
2. SQL 속도 올리기
중복 쿼리를 제거함에 따라 어느정도의 향상은 확실히 있었습니다. 다만 기존에도 중복되는 쿼리수가 많지는 않았기에 사용자 입장에서의 속도차이는 그리 크지 않았습니다. 따라서, 본질적인 문제인 SQL을 뜯어보기로 하였습니다.
class MessageViewSet(viewsets.ModelViewSet):
queryset = Message.objects
def list(self, request, *args, **kwargs):
messages = (self.get_queryset()
.select_related()
.prefetch_related())
...
# SQL이 실질적으로 발생되는 부분
page = self.paginate_queryset(messages)
if page is not None:
serializer = self.get_serializer(page, many=True)
return self.get_paginated_response(serializer.data)
serializer = self.get_serializer(messages, many=True)
return Response(serializer.data)검색은 30개씩 페이지네이션을 통해 결과를 보여줍니다. 해당 부분에서 발생되는 SQL은 대략적으로 아래와 같습니다.
# Pagination에서 발생되는 Count SQL
Select Count(*) FROM message WHERE ~~~
Between 2017-01-01 and 2021-12-31 LIKE %검색내용%;
# 검색 결과가 담겨 있는 SQL
Select message.content ~~~ FROM message WHERE ~~~
Between 2017-01-01 and 2021-12-31 LIKE %검색내용% Orderby message.created Desc LIMIT 30;
# 그 외 조인에서 발생되는 SQL
Select ~~~ FROM (조인 대상 테이블);실질적으로 퍼포먼스를 저하 시키는 부분은 메시지 테이블의 전체 Count(*), 검색 결과를 가져오는 SQL 입니다. 두 부분이 전체 검색 시간의 90%를 1:1 비율로 시간을 차지합니다. 따라서, 해당 부분에서 최적화가 필요하다는 판단을 하게 됩니다.
2-1. ORM 최적화
이미 오랜시간 동안 발생되었던 문제였기에 대부분의 ORM 최적화는 되어있었습니다. 여태 쌓아온 데이터를 갑자기 변경하거나 삭제하는 것에는 무리가 있으므로 이미 존재하는 데이터를 어떻게 빠르게 가져오게 할 수 있을까에 대한 것들을 많이 생각해보았습니다.
- Postgresql 인덱싱 작업 (Explain 분석)
- Serializer 변경 (Third-party library 이용)
- SearchVector, Django full text search 적용 (GIN Index)
2-2. Postgresql 인덱싱 작업 & Explain 분석
데이터베이스에 인덱스가 걸린 것과 안걸린 것의 속도차이는 매우 크다는 것을 대부분의 사람들은 알고 있을 것입니다. 인덱스가 없다면 생성해줘야 할 것이고, 있다 하더라도 해당 인덱스를 잘 이용하는지에 대한 분석이 필요하기에 Explain analyze 명령어를 이용해보았습니다.
Explain analyze를 사용하면 Postgres에서 생성한 Query Plan과 예상 cost등을 볼 수 있습니다. 하지만, 처음 보면 이해할 수 없는 글자들이 많기에 visualization 툴을 이용하였습니다.
explain.dalibo.com
explain.dalibo.com
해당 사이트에 Query Plan을 입력하면 이해하기 쉬운 그림을 통해 결과를 보여줍니다.
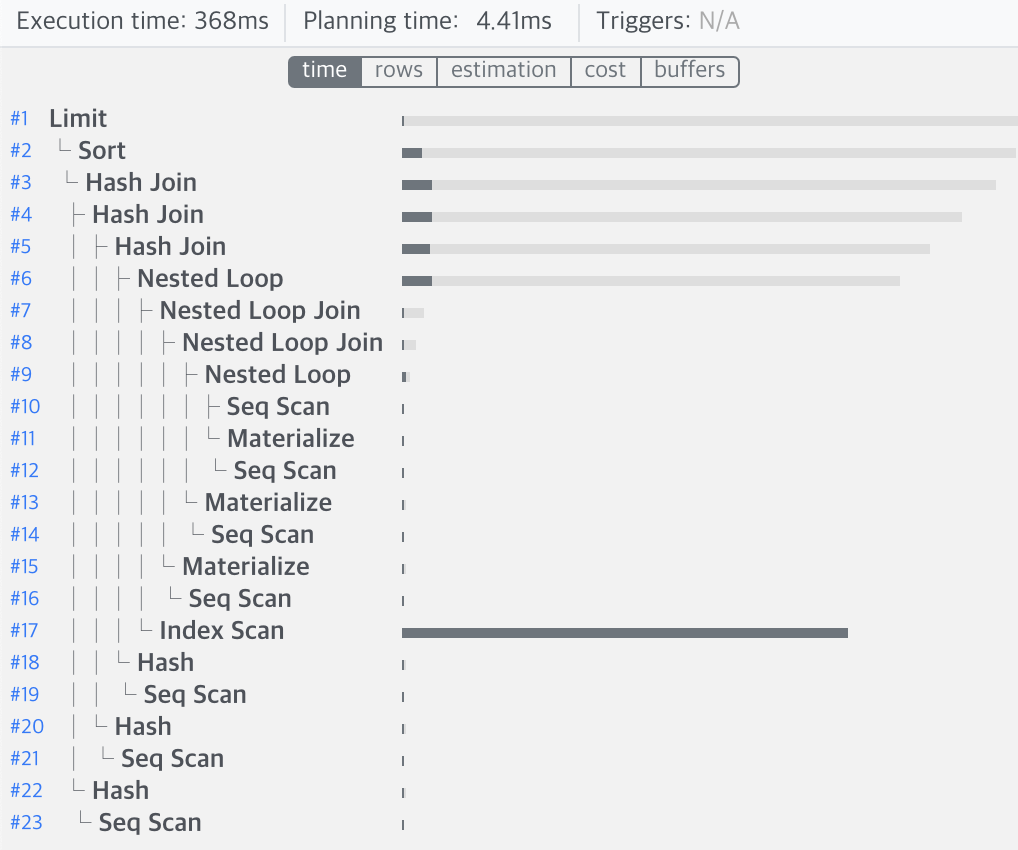
위의 사진을 보면 인덱스 스캔이 대부분의 시간을 차지하는 것을 확인할 수 있습니다. 또한, 인덱스 cond(조건)역시 created로 걸려 있었기에 여기에서 Message 테이블의 created 필드에 인덱스를 걸면 좋을 것이라는 가설을 세워봅니다.
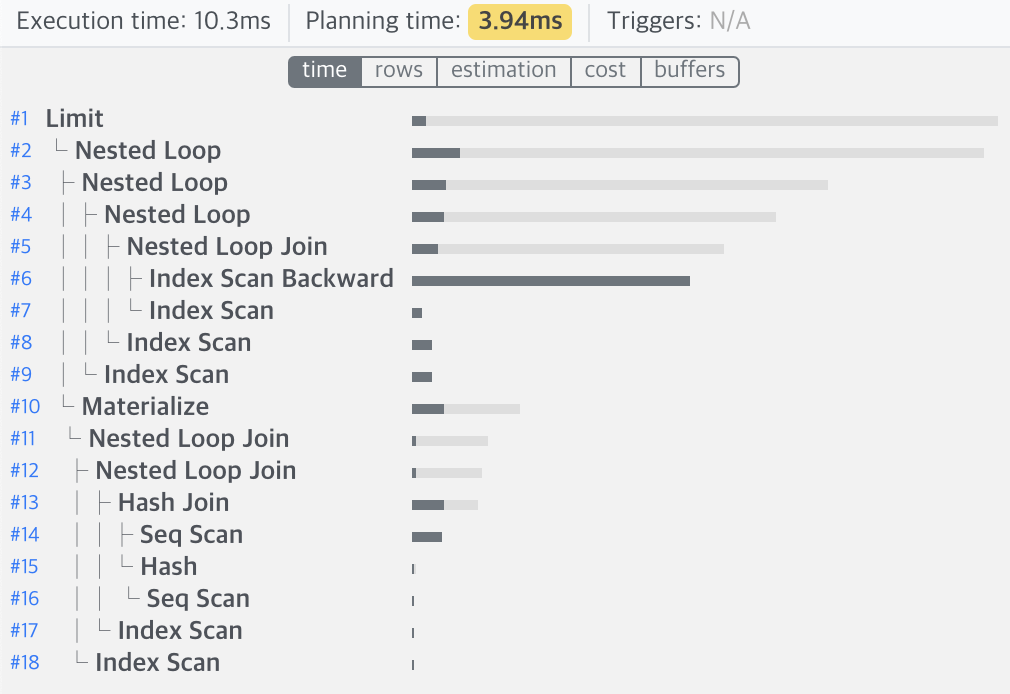
created에 인덱스를 건 것만으로 무려 쿼리속도가 30배 이상 빨라진 것을 확인하게 되었습니다. 이정도의 개선이면 만족할 수 있는 performance 라고 생각을 하고 있었습니다.
2-3. 실제 데이터는 다르다
위의 실험을 진행한 환경은 dummy데이터를 약 50m개 만들어서 진행한 결과입니다. 하지만 실제 덤프된 데이터를 통해 똑같이 측정해보니.. 웬걸, 인덱스를 걸기 전과 속도차이가 전혀 없었습니다!
데이터의 row에만 집중하고 분포(실제 환경)에는 신경을 안쓰다보니 상반된 결과가 나왔던 것입니다.
이때부터, 정말 모든 방법들을 시도해보기 시작합니다.. 인덱스, 복합 인덱스 등 굉장히 많은 시간을 쏟아 부었음에도 어마어마한 데이터의 양에는 장사없다는 것을 몸소 깨닫게 됩니다.
(pg_hba.conf 설정, vacuum, analyze, Index rebuild 등 안해본 것이 없습니다)
3. serializer 변경
DRF serializer 성능 issue에 대한 문제가 많다는 글들을 많이 봐왔기에 혹시나 하는 마음에 DRF 공식 문서에도 나와있는 Third-party Serializer를 찾아 적용해보기로 하였습니다.
https://github.com/clarkduvall/serpy
GitHub - clarkduvall/serpy: ridiculously fast object serialization
ridiculously fast object serialization. Contribute to clarkduvall/serpy development by creating an account on GitHub.
github.com
생각보다 간단한 사용법을 가지고 있어 적용하는데 큰 어려움을 겪지는 않았지만, 퍼포먼스의 향상은 미미한 수준에 그치는 것을 확인할 수 있었습니다. 즉, DRF Serializer에는 문제가 없다는 뜻입니다.
이야기가 너무 길어져 다음편에 이어 작성하도록 하겠습니다. 금방 찾아올게요!
'SW개발 > 개발이야기' 카테고리의 다른 글
| [테스트]테스트 커버리지 0%에서 98%까지의 경험기 1 (3) | 2021.11.28 |
|---|---|
| [Django]검색 퍼포먼스를 향상하기까지의 과정 2 (2) | 2021.09.29 |
| [Django]Openstack Swift 401 Authentication failed 삽질기 (0) | 2021.07.29 |
| [Docker]초짜의 삽질기 리뷰 마지막 (feat. Django Dockerizing) (2) | 2021.07.10 |
| [Docker]초짜의 삽질기 리뷰 2 (feat. Django Dockerizing) (2) | 2021.07.10 |